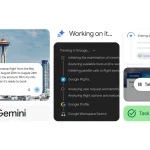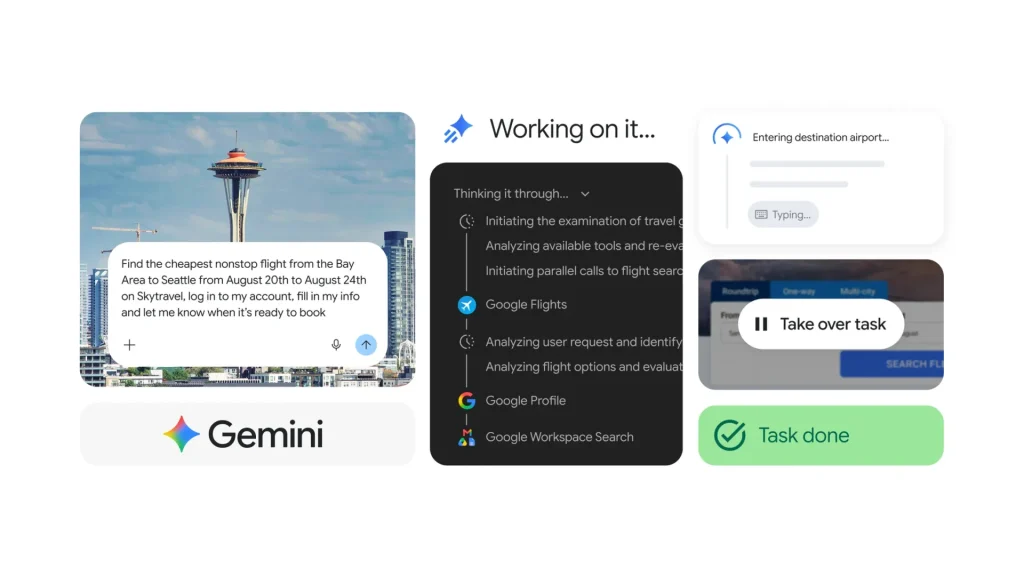















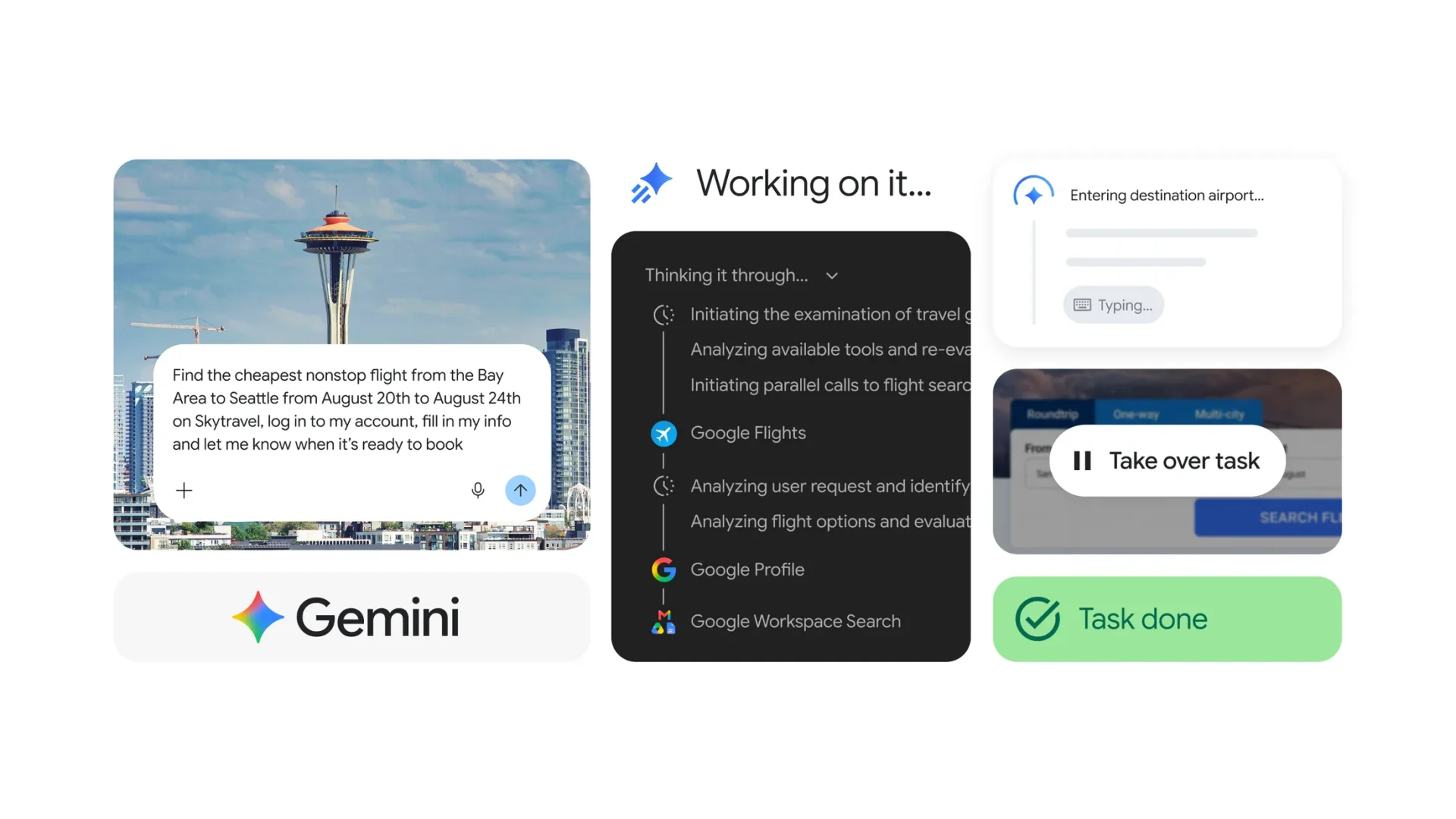
Google ประกาศอัปเดต Gemini Spark ด้วยฟีเจอร์ใหม่ที่ช่วยให้ AI สามารถทำงานบนเว็บผ่าน Google Chrome ได้โดยตรง ทำให้ผู้ใช้ไม่ต้องเสียเวลาคลิกหรือกรอกข้อมูลซ้ำ ๆ ในงานประจำวัน Google เดินหน้าอัปเกรด Gemini Spark ให้เป็น AI Agent ที่ทำงานแทนผู้ใช้ได้มากขึ้น ล่าสุดเพิ่มความสามารถในการทำงานร่วมกับ Google Chrome เพื่อจัดการงานบนเว็บไซต์แบบอัตโนมัติ พร้อมขยายการให้บริการแก่สมาชิก Google AI Pro ในกว่า