




Now Reading: นักวิจัยคิดค้นเทคโนโลยีบีบอัดเสียง Lossless ยุคใหม่ ย่อขนาดไฟล์ได้ 8 เท่า โดยไม่เสียคุณภาพด้วย AI !
-
01
นักวิจัยคิดค้นเทคโนโลยีบีบอัดเสียง Lossless ยุคใหม่ ย่อขนาดไฟล์ได้ 8 เท่า โดยไม่เสียคุณภาพด้วย AI !

นักวิจัยคิดค้นเทคโนโลยีบีบอัดเสียง Lossless ยุคใหม่ ย่อขนาดไฟล์ได้ 8 เท่า โดยไม่เสียคุณภาพด้วย AI !
เทคโนโลยีการบีบอัดไฟล์เสียงแบบ Lossless ในปัจจุบัน ส่วนใหญ่สามารถลดขนาดไฟล์จากต้นฉบับลงได้เพียงครึ่งเดียวเท่านั้น แต่ล่าสุดมีทีมนักวิจัยจากมหาวิทยาลัยแบกแดด ประเทศอิรัก สามารถบีบอัดไฟล์เสียงได้ถึง 8:1 หรือ 8 เท่า โดยไม่สูญเสียรายละเอียดสำคัญที่หูมนุษย์สามารถแยกแยะได้
ทีมนักวิจัยได้นำเทคนิค ‘Variational Autoencoders’ (VAEs) ซึ่งเป็นโมเดล AI ประเภท Neural Network ที่ถูกออกแบบมาเพื่อการบีบอัดข้อมูลโดยเฉพาะ มาทดลองกับไฟล์เสียงจากคลังของ BBC ไม่ว่าจะเป็นเพลง, เสียงพูด, เสียงสภาพแวดล้อม, เสียงเครื่องจักร ไปจนถึงเสียงสัตว์
โดยไฟล์ทั้งหมดมีคุณภาพมาตรฐาน 44.1 kHz/16-bit และมีความยาวตั้งแต่เสี้ยววินาที ไปจนถึงเกือบ 5 นาที ก่อนจะแปลงเป็นเสียง Mono รวมแล้วความยาวประมาณ 17 นาที ด้วยกัน
ทีมวิจัยได้ทดสอบการบีบอัด 4 ระดับ ได้แก่ 1:1 (ไม่บีบอัด), 2:1, 4:1 และ 8:1 โดยพบว่าการตั้งค่า 8:1 ให้ผลลัพธ์ที่ดีที่สุด ไฟล์มีขนาดเล็กลงอย่างมาก ความผิดพลาด (error) อยู่ในระดับต่ำ และใช้เวลาประมวลผลอยู่ในระดับที่เหมาะสมสำหรับการทำวิจัย โดยเรียกไฟล์เสียงการกระบวนการนี้ว่า ‘Reconstructed Audio’ หรือถูกสร้างขึ้นใหม่
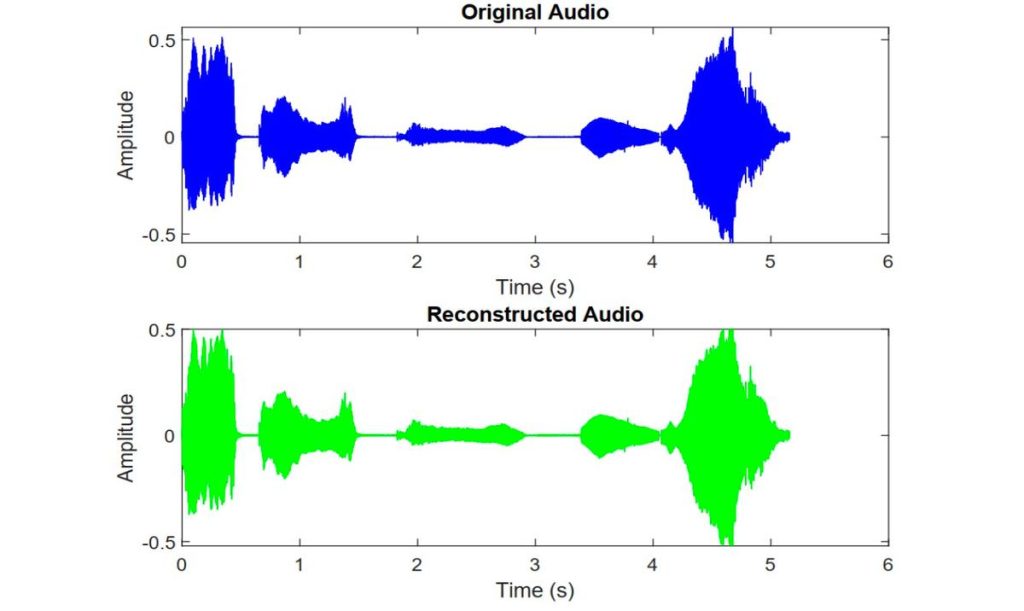
- อัตราส่วนสัญญาณต่อสัญญาณรบกวน (SNR) มีค่าเฉลี่ยอยู่ที่ 26.33 dB และมี wide range ตั้งแต่ 8.04 dB ในระดับต่ำสุด ไปจนถึง 50.08 dB ในระดับสูงสุด
- ขณะที่ค่า Mean Square Error (MSE) มีค่าเฉลี่ยอยู่ที่ –52.58 dB โดยมีช่วงตั้งแต่ –65.08 dB ไปจนถึง –40.01 dB
ตัวเลขเหล่านี้ชี้ให้เห็นว่าไฟล์เสียงแบบ reconstructed ยังมีคุณภาพใกล้เคียงกับไฟล์ต้นฉบับ แม้ว่าประสิทธิภาพจะแตกต่างกันไปตามแต่ละตัวอย่างเสียงที่ทดลองก็ตาม
หลักการทำงานของ Variational Autoencoder (VAEs)
ความพิเศษของเทคนิค VAEs คือ encoder ไม่ได้สร้างรหัสตายตัว แต่จะคำนวณค่าเฉลี่ย (mean) และความแปรปรวน (variance) เพื่อสร้าง ‘พื้นที่ความน่าจะเป็น’ (probability distribution) จากนั้นจึงสุ่มค่ารหัสแฝง (latent code) ขึ้นมา วิธีนี้ช่วยให้ระบบมีความยืดหยุ่น และเก็บรายละเอียดได้ดีกว่านั่นเอง
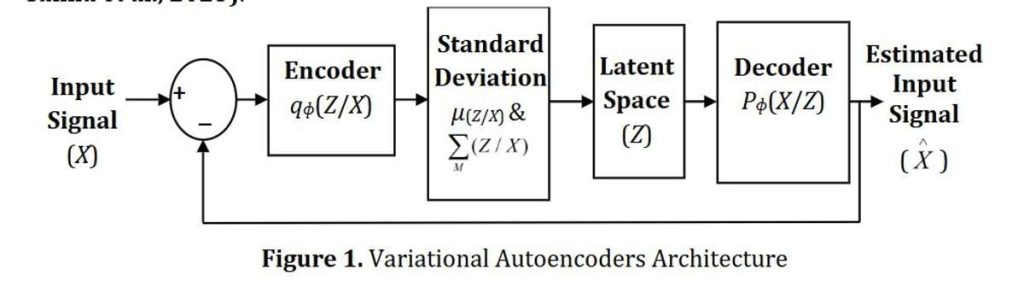
- Encoder: ลดเสียงดิบให้เป็น ‘รหัสย่อ’ หรือ representation ขนาดเล็ก
- Decoder: สร้างเสียงกลับมาใหม่จากรหัสดังกล่าว จึงเป็นที่มาของคำว่า ‘reconstructed’
ตัวโมเดลจะต้องถูกฝึกอย่างปราณีตที่สุดเพื่อให้สามารถทำงานได้ดังเป้าที่ตั้งไว้ ด้วยอัลกอริทึม Adam optimizer ทั้งหมด 30 รอบ ด้วยกัน โดยมีวัตถุประสงค์ 2 ส่วน คือ
- ทำให้เสียงที่สร้างกลับมาใกล้เคียงกับต้นฉบับที่สุด
- ใช้ KL divergence เพื่อจัดระเบียบ latent space ให้รหัสที่ได้มีประสิทธิภาพในการบีบอัด
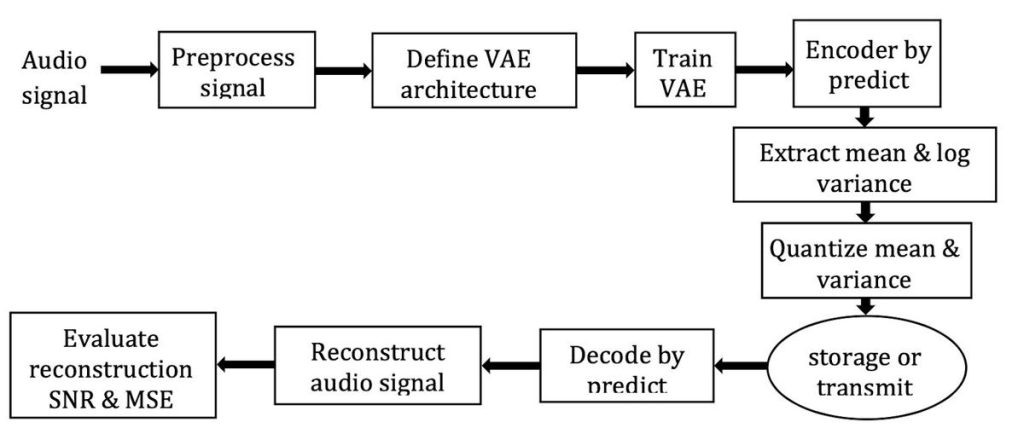
| ภาพจาก: Journal of Engineering
ข้อจำกัดในปัจจุบัน
แม้ผลลัพธ์จะทำได้ในระดับที่น่าสนใจ แต่ก็ยังมีข้อจำกัดต่าง ๆ มากมาย ไม่ว่าจะเป็น
- ความเร็วต่ำ: ในการเข้ารหัสเพลง 3 นาที อาจต้องใช้เวลากว่า 5 ชม. ในการประมวลผล
- ขอบเขตยังจำกัด: ปัจจุบันทดลองเฉพาะไฟล์ Mono เท่านั้น ยังไม่รองรับ Stereo หรือ Multi-channel
- ความหมายของคำว่า ‘Lossless’: แม้จะใช้คำว่า lossless แต่เสียงที่สร้างขึ้นใหม่ไม่ได้เหมือนต้นฉบับแบบบิตต่อบิต ยืนยันได้จากค่า error ที่ยังมีอยู่
VAEs อาจเป็นอนาคตใหม่ของไฟล์เพลง
ถ้าหากสามารถขงัดข้อกำจัดต่าง ๆ ในปัจจุบันไปได้ กระบวนการนี้จะช่วยให้สามารถบีบอัดไฟล์ที่มีขนาด 50MB ให้เหลือเพียง 6MB เท่านั้น ซึ่งจะช่วยให้การเก็บไฟล์เพลงสามารถทำได้ง่ายมากขึ้น ลดภาระทั้งที่จัดเก็บ รวมไปถึงแพลตฟอร์มสตรีมมิงออนไลน์ และกินแบนด์วิดท์น้อยลง เหมาะสำหรับอุปกรณ์พกพาขึ้นอีกหลายเท่า
ที่มา: Headphonesty












Advertisement